deepsing
Generating Sentiment-aware Visual Stories using Cross-modal Music Translation
Can machines dream while listening to music? Is it possible to turn music into images in a meaningful way? deepsing was born to materialize our idea (by Stavros Doropoulos and - to a lesser extent - me, and materialized after many discussions, coffees, and long walks) of translating audio to images inspired by Futurama Holophoner. In this way, deepsing is able to autonomously generate visual stories which convey the emotions expressed in songs. The process of such music-to-image translation poses unique challenges, mainly due to the unstable mapping between the different modalities involved in this process. To overcome these limitations, deepsing employs a trainable cross-modal translation method, leading to a deep learning method for generating sentiment-aware visual stories.
The proposed method is capable of synthesizing visual stories according to the sentiment expressed by songs. The generated images aim to induce the same feelings to the viewers, as the original song does, reinforcing the primary aim of music, i.e., communicating feelings. deepsing employs a trainable cross-modal translation method to generate visual stories, as shown below:
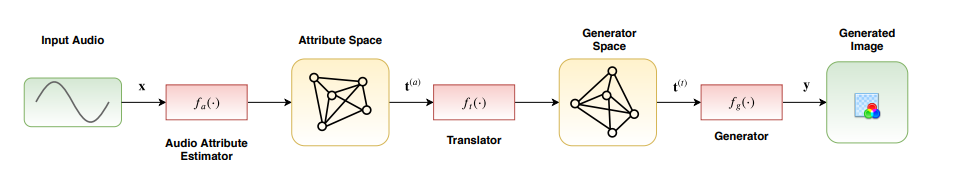 The process of generating a visual story is also illustrated bellow
The process of generating a visual story is also illustrated bellow
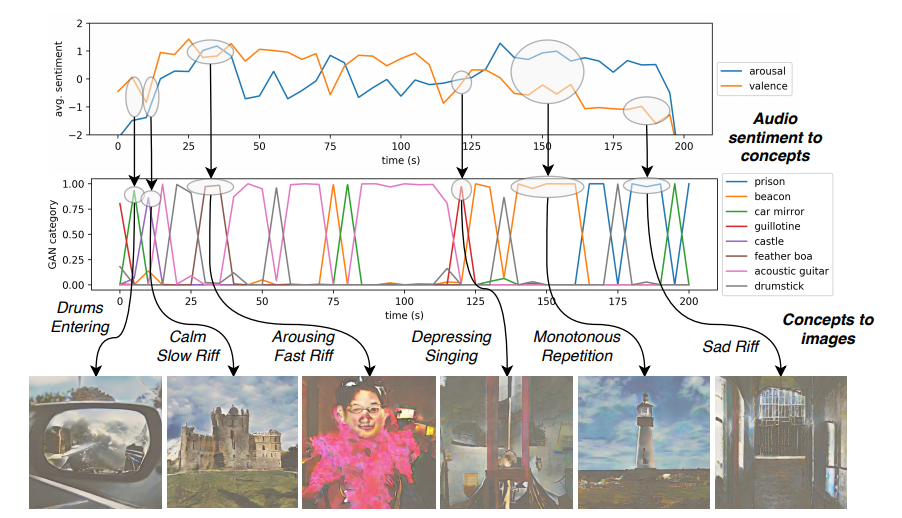
We have implemented a front-end to our method at deepsing.com You can find an example of a purely machine-generated visual story using our method here. Note that the version available at deepsing.com is currently lacking many essential features, but demonstrates the basic concept of our idea! Also, note that song lyrics are NOT used in this process, since the proposed method currently works based SOLELY on the sentiment induced by the audio!
Furthermore, you can find more information in our paper, while we have also released the code of our method on GitHub. Feel free to hack with us and share your opinions with us!
If you use deepsing in your research, please cite our paper:
@article{passalis2021deepsing,
title={deepsing: Generating sentiment-aware visual stories using cross-modal music translation},
author={Passalis, Nikolaos and Doropoulos, Stavros},
journal={Expert Systems with Applications},
volume={164},
year={2021},
}
You are free to use the generated videos in any way you like, as long as you keep the deepsing logo.